Don’t share your private data on the internet, this example works as a proof of concept and shouldn’t be used in production environments.
Background
Here in Spain a lot of Financial institutions, Banks, Fintech’s are doing a service that allows you to connect all your bank accounts from different banks and see your balance, recollect some data etc… in one unique place.

We just tried to reproduce this with a basic POC that does the same using a Serverless Architecture , Chrome and Puppeteer.
“Build your own aggregator and add functionalities that your bank does not have… or just create your own metrics about your expenses the way you prefer”
Initial Requirements
To start this project you will need:
- 2+ Bank accounts (from different banks if possible)
- 1 Cloud provider (We used GCP free tier with billing activated)
- 60 minutes of your time
Get Started
Create and setup your project in your cloud provider, We use GCP you can check the quick starter here, but the code should work the similar way with other cloud providers (we will give azure functions and AWS lambda example soon).
Setup and authenticate into your Cloud Provider
# 1. Login GCP
$ gcloud auth login
# 2. Assign a project for your function
$ gcloud config set project PROJECT_NAME
Start your Node project and install dependencies :

Initial Puppeteer setup
Puppeteer is a Node library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol. Puppeteer runs headless by default, but can be configured to run full (non-headless) Chrome or Chromium.
At this point we have a folder structure similar to:
bank-aggregator/
├── node_modules/
├── index.js
├── package.json
├── package-lock.json
we will start our code by preparing our scrapping service in ./index.js
Now run the previous code and see Puppeteer opens your browser with your bank website:
node -e 'require("./index").runService()'
We used a basic Puppeteer configuration where headless mode is set to false in order to see how things work and check if scrapping function is running.
Web Scrapping your bank with Puppeteer
Next, we will reproduce all the steps and behaviours users do when accessing their bank accounts; then we will get the results needed for our aggregator.
- Check Puppeteer API to know how it works
- Reproduce your steps to login and see your online banking balance using the CSS selectors of your bank’s page or use the Puppeteer recorder chrome extension, that auto generates code compatible with Puppeteer as following.
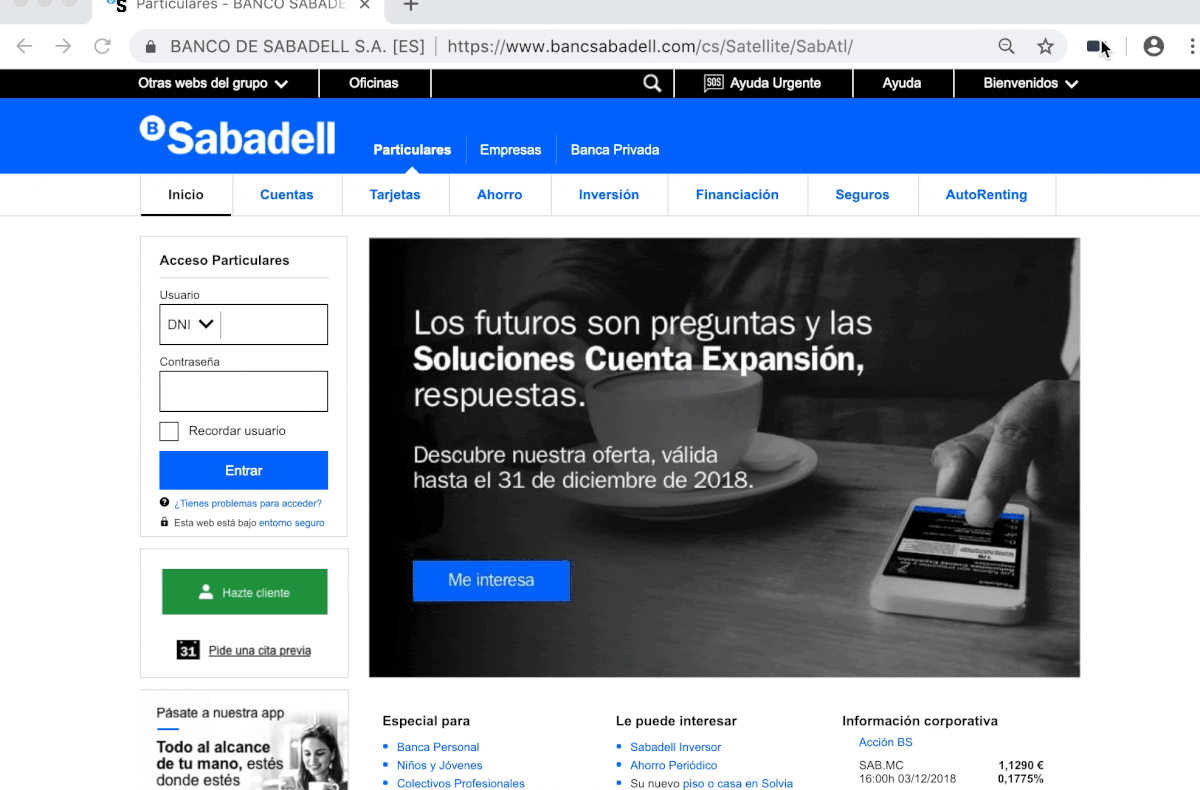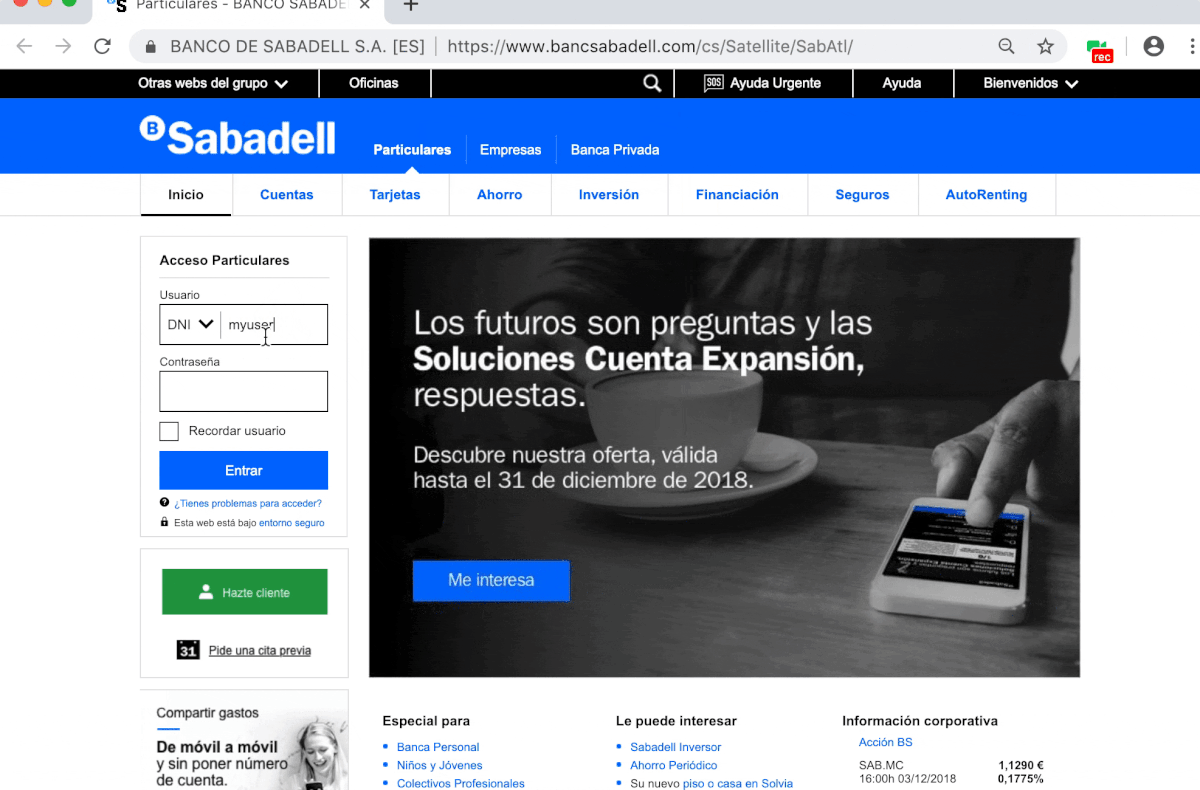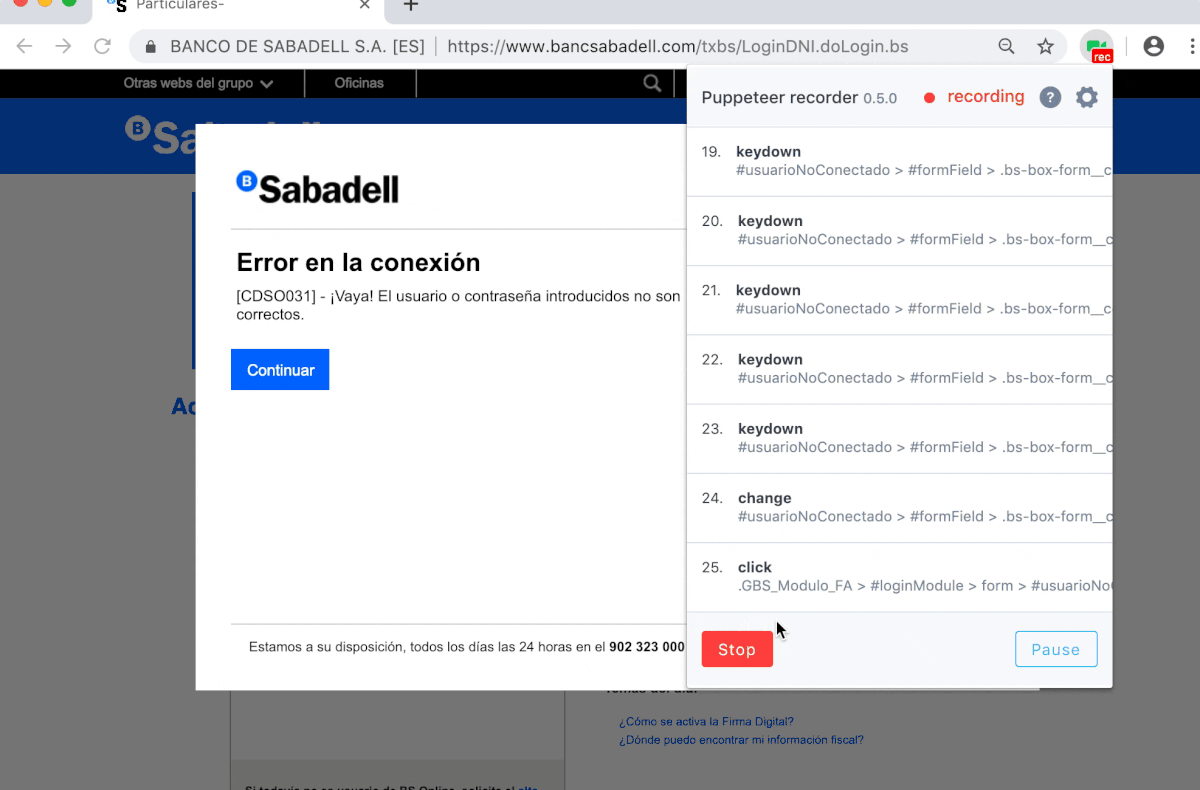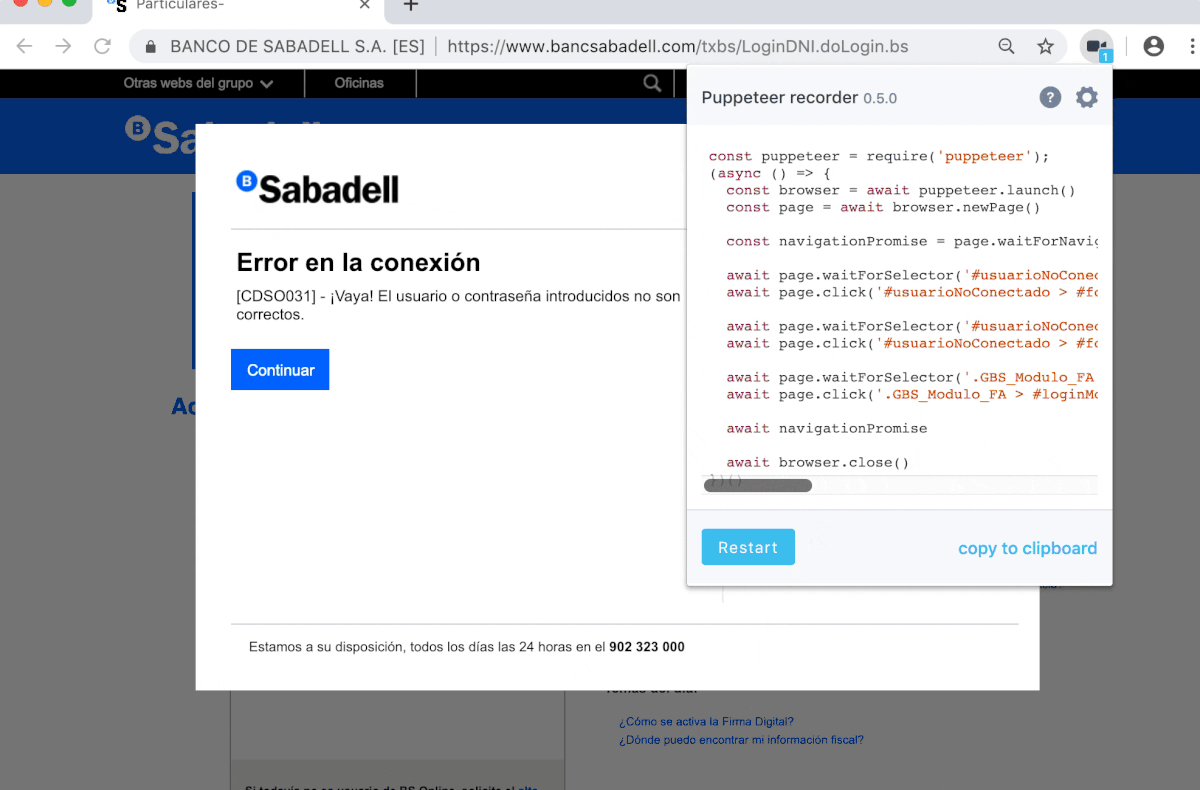
In the step we used wrong credentials only to give an example how you can get the auto generated code from Puppeteer recorder chrome extension
At this point you should be able to log in to your bank dashboard and get details about your transactions/ balance or anything you need, your code should look similar to the following example:
Running the code locally, you should get your account details
$ node -e 'require("./index").runService('USERNAME' , 'PASSWORD')'[ 'CUENTA EXPANSIÓN',
'ESXX XXXX XXXX XXXX XXXX XXXX',
'Available',
'99999.99999,9999999 €' ]
Deployment
We now have a working scrapping app. Next, it is time to deploy it to our cloud provider , don’t forget that this service requires that your cloud provider can run Chrome or Chromium working in headless mode.
Before deploying
- Setup Puppeteer to run in headless (check the code here)
const browser = await puppeteer.launch({headless: true,
args:['--no-sandbox']
});
- Refactor your code to handle request/response arguments , check the Github repository here
Deploy
Deploy to Google Cloud Functions using command line (check here npm scripts for deployment)
$ gcloud functions deploy NAME_OF_FUNCTION --runtime nodejs8 --trigger-http --memory 2048
Notes & Optimisations
Don’t share your private data in the internet , this example works as a proof of concept and shouldn’t be used in production environments. Cost and bad code practices or malicious usage aren’t our responsibilities
- Code: This is sample code working as a Proof of concept, the code is not ready nor optimised for production, the project does not handle errors and checks that are normally applied in production, the goal kept it as simple as possible.
- Performance: The project does not have any optimisation, and puppeteers has considerable tweaks to improve times in serverless architecture, you may check configurations with your cloud provider and check this issue about some slowness of Puppeteer on GCP
- Security: We are running an unsafe environment and not using any encryption or security rule, every bank could act differently when they are accessed by a web scrapping tool. Be careful in this implementation
Final thoughts
You can find a demo repository on Github that walks you through the article and has more bank integrations
The article is an overview to give an example on how we can use Serverless Architecture to produce a new kind of business ideas.
Feel free to provide feedback and PR’s to integrate new banks to the repository.
Be aware of your cloud configuration to avoid undesired costs or malicious usage
Resources
Some useful resources
- ebidel/puppeteer-functions
- Cloud Functions Node.js Emulator | Cloud Functions Documentation | Google Cloud
Thanks again Wassim Chegham